Key Takeaways
- It is feasible to build a secure, privacy-preserving visualization tool for sensitive microbiome data by using serverless edge functions to keep all computations within a secure environment.
- The developed module for FAIRDatabase allows researchers to perform composition-aware beta diversity analysis and generate interactive visualizations (PCoA plots, heatmaps) without ever downloading the raw data.
- A user study with ten domain experts confirmed the module's high usability, achieving an excellent System Usability Scale (SUS) score of 86.8 and demonstrating its value for exploratory analysis.
TL;DR
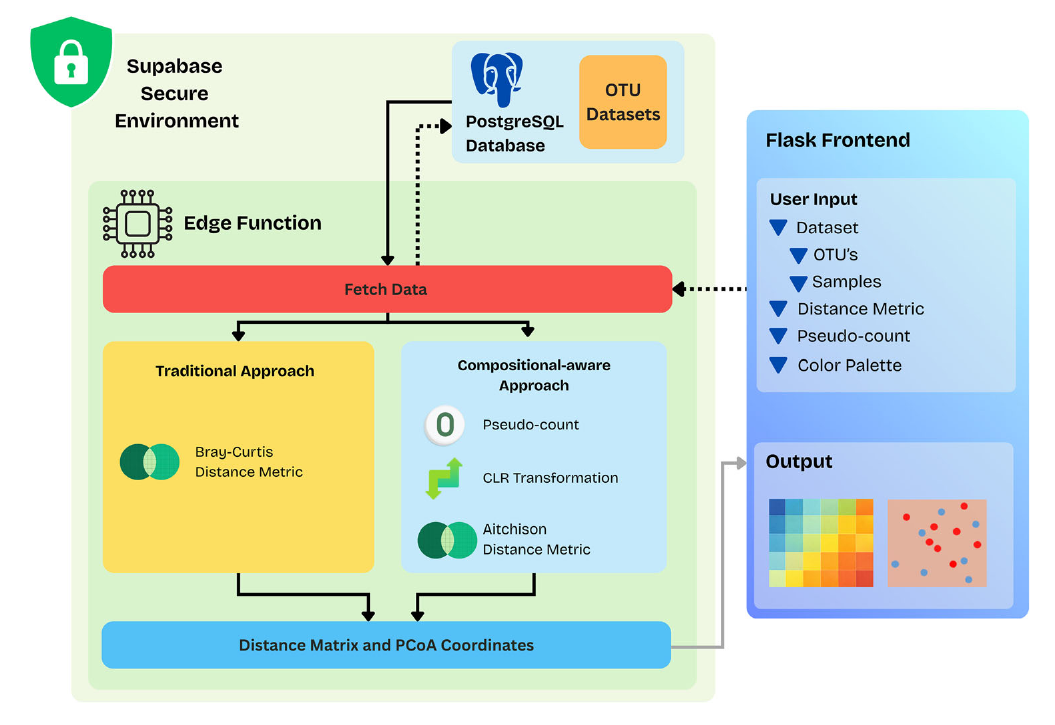
Microbiome research generates vast amounts of data, much of which is linked to individuals and thus highly sensitive. Privacy regulations like GDPR and the compositional nature of this data create significant challenges for sharing and analysis, hindering reproducibility and collaboration. Existing visualization tools often require researchers to download the raw data, which poses a major security risk and is often not permissible, creating a bottleneck for scientific discovery. This paper presents a module for FAIRDatabase, a secure data infrastructure, that performs composition-aware beta diversity analysis and visualization. The key innovation is using serverless edge functions to run computations (like centered log-ratio transforms and distance calculations) close to the database. This means sensitive raw data never leaves the secure environment. The system generates interactive visualizations like PCoA plots and heatmaps, allowing researchers to explore data without compromising security.
Why Does It Matter?
This paper provides a crucial blueprint for balancing data analysis with strict privacy regulations (like GDPR). It demonstrates how edge computing can be integrated into FAIR data infrastructures to enable powerful visualization and exploratory analysis without exposing raw data. This approach is a significant step towards enabling reproducible and collaborative research on sensitive human-associated data, offering a model that can be adopted across many scientific fields.
FAIR vs. Privacy
This paper tackles the classic tension between making data FAIR (Findable, Accessible, Interoperable, Reusable) and upholding stringent privacy, especially with sensitive human microbiome data. The core insight is that these two goals are not mutually exclusive if the architecture is re-imagined. Instead of direct data access, the study proposes using privacy-preserving edge functions. This clever approach keeps sensitive raw data within a secure environment, performing all computations remotely. Only aggregated, non-identifiable results are sent to the user for visualization and analysis. This method makes the data functionally *Accessible* and *Reusable* for scientific inquiry without ever exposing the raw, potentially re-identifiable information, demonstrating that through thoughtful design, we can achieve the goals of open science without compromising participant privacy.
Compute @ Edge
The 'Compute @ Edge' strategy offers a sophisticated solution to the data analysis versus privacy dilemma in microbiome research. It utilizes serverless edge functions to create a secure, ephemeral computational middle-ground. This architecture ingeniously processes sensitive data close to the data source and user, primarily to enhance security rather than just reduce latency. Crucially, raw microbiome data never leaves the secure backend environment; computations are executed at the edge, and only the derived, non-sensitive results (e.g., visualization coordinates) are returned to the client. This embodies the principle of privacy-preserving analytics, enabling powerful data exploration without exposing raw data. The paper acknowledges a key trade-off: this model excels at short-lived, stateless operations but is unsuitable for heavy, long-running computations, defining its role as a specialized tool for secure, interactive analysis.
Relatives Only
The heading 'Relatives Only' poignantly encapsulates the paper's central thesis on balancing microbiome data utility with stringent privacy. This research crafts a digital fortress, the FAIRDatabase, where sensitive human data is the protected family that must never leave its secure home. The 'relatives' are not researchers but specialized edge functions - trusted computational processes authorized to interact with the data directly within this secure environment. By performing analyses 'at the edge,' the system ensures that only the anonymized, aggregated insights (the 'family news') are shared externally, while the raw, identifiable sensitive data remains confidential. This architecture directly addresses the ethical dilemma that human microbiome profiles can uniquely identify individuals, thus creating a 'relatives only' model for data interaction that prioritizes robust security and responsible science.
SUS: Excellent
The 'SUS: Excellent' finding signifies a major success for the research, confirming the exceptional usability of the developed data visualization module. Achieving a high mean System Usability Scale (SUS) score of 86.8 from ten domain experts is a powerful validation of the system's design. This result is particularly noteworthy given the module's complex task of enabling sophisticated microbiome data analysis while adhering to strict privacy constraints through edge functions. The 'excellent' rating demonstrates that the authors successfully created an intuitive and effective interface that masks underlying architectural complexity. It provides strong evidence that the tool is not merely a technical proof-of-concept but a genuinely valuable and user-centric solution for researchers, allowing for seamless exploratory analysis without a steep learning curve.
PoC & Next Steps
The paper presents a potent Proof-of-Concept, validated by a high usability score (SUS 86.8) and a successful implementation of its core architectural innovation. The use of edge functions demonstrates that complex, composition-aware microbiome analysis can be performed securely without moving sensitive data, directly addressing a critical bottleneck in the field. For next steps, the formative evaluation clearly points towards the need to expand analytical capabilities with additional visualization types like biplots. A crucial follow-up is to implement guided decision support to help non-expert users navigate complex methodological choices, a key piece of feedback from the study. Ultimately, progressing to a larger, formal summative evaluation will be essential to solidify these findings and encourage wider community adoption.
Stay Updated with Our Research
Get notified when we publish new AI-analyzed papers and research insights:
Subscribe to Newsletter